


Nächste Seite: Der WWW-Agent zur Vervollständigung
Aufwärts: Dokumentation
Vorherige Seite: Formatbeschreibung der Netzwerk-Dateien
Inhalt
Zu Beginn der Arbeit wurde ein Webcrawl der Webseiten der
Christian-Albrechts-Universität erstellt. Dazu wurden die kostenlos
verfügbaren Quelltexte eines Suchagenten7.2benutzt. Es bedurfte einiger Modifikationen der Quelltexte, damit die
gesuchte Linkstruktur der Webseiten gespeichert wird. Als Startseite des
Webcrawls wurde ``http://www.uni-kiel.de/index.html'' benutzt. Es wurden
nur Verweise innerhalb der Domain ``*.uni-kiel.de'' verfolgt. Insgesamt
wurden 184858 Knoten und 2411553 Verbindungen gefunden. Die mittlere
Konnektivität liegt mit 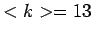 deutlich höher als in anderen Webcrawls (Tab. 1.1).
Aufgrund der häufig schwierig zu identifizierenden Art des Ziels eines
Verweises sind in diesem Webcrawl jedoch nicht nur Webseiten (HTML)
einbezogen worden. In Abbildung A.2 und A.3
sind die Inlink-Verteiung und die Outlink-Verteilung dargestellt.
deutlich höher als in anderen Webcrawls (Tab. 1.1).
Aufgrund der häufig schwierig zu identifizierenden Art des Ziels eines
Verweises sind in diesem Webcrawl jedoch nicht nur Webseiten (HTML)
einbezogen worden. In Abbildung A.2 und A.3
sind die Inlink-Verteiung und die Outlink-Verteilung dargestellt.
Insgsamt ist dieser Webcrawl zu klein für die durchgeführten
Untersuchungen und nicht mit den Vorraussetzungen (vgl. 2.1) der Modelle des
WWW konsistent.
Abbildung:
Doppelt-logarithmischer Plot der Inlink-Verteilung eines
Webcrawls der Seiten der Christian-Albrechts-Universität: Wahrscheinlichkeit 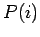 einen Knoten mit
einen Knoten mit 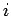 Inlinks zu finden.
Inlinks zu finden.
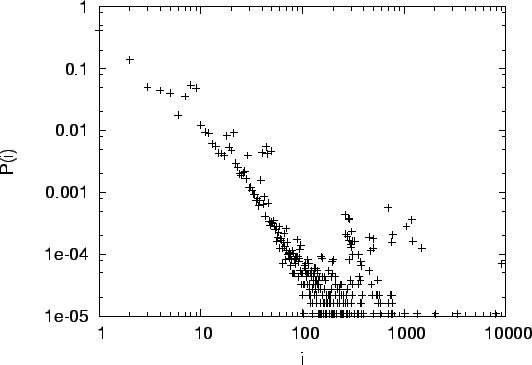 |
Abbildung:
Doppelt-logarithmischer Plot der Outlink-Verteilung eines
Webcrawls der Seiten der Christian-Albrechts-Universität: Wahrscheinlichkeit 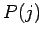 einen Knoten mit
einen Knoten mit 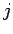 Outlinks zu finden.
Outlinks zu finden.
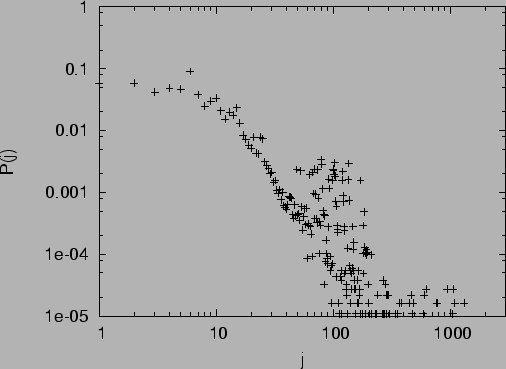 |
Nächste Seite: Der WWW-Agent zur Vervollständigung
Aufwärts: Dokumentation
Vorherige Seite: Formatbeschreibung der Netzwerk-Dateien
Inhalt
Autor:Lutz-Ingo Mielsch