


Nächste Seite: Die unkorrelierte Verteilung
Aufwärts: Gemeinsame In- und Outdegree
Vorherige Seite: Einleitung
Inhalt
Abbildung:
Gemeinsame Verteilung
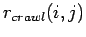 des Webcrawls.
Die Färbung gibt den Logarithmus der Wahrscheinlichkeit an, einen Knoten
mit Indegree
des Webcrawls.
Die Färbung gibt den Logarithmus der Wahrscheinlichkeit an, einen Knoten
mit Indegree 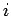 und Outdegree
und Outdegree 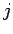 zu finden. Die Verteilung ist auf
zu finden. Die Verteilung ist auf
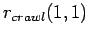 normiert.
normiert.
 |
Ausgehend von dem Netzwerk des Webcrawls wurde
die gemeinsame Verteilung
des Webcrawls
bestimmt. Dazu erzeugte ein Programm zunächst eine Liste
aller Knoten mit deren jeweiliger Anzahl Inlinks und Outlinks. Das zweite
Programm summiert über diese Liste für gleiche Wertepaare der Inlinks und
Outlinks. Als Ergebnis erzeugt es eine Datei mit den gesuchten
Informationen zur Verteilung 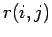 - Inlinks, Outlinks, Knotenanzahl. Um
eine vollständige Erfassung der Verteilung zu ermöglichen, werden die
Datenpunkte in einem Hash abgelegt, wobei der In- und Outdegree als
Schlüssel verwendet wurde. Das erlaubt eine sehr viel effizientere
Speicherausnutzung als eine Matrix. Diese vollständige Auswertung
ermöglicht zur Prüfung der Konsistenz der gemeinsamen Verteilung
die Bestimmung der
einzelnen In- und Outdegree Verteilungen durch die Summationen
- Inlinks, Outlinks, Knotenanzahl. Um
eine vollständige Erfassung der Verteilung zu ermöglichen, werden die
Datenpunkte in einem Hash abgelegt, wobei der In- und Outdegree als
Schlüssel verwendet wurde. Das erlaubt eine sehr viel effizientere
Speicherausnutzung als eine Matrix. Diese vollständige Auswertung
ermöglicht zur Prüfung der Konsistenz der gemeinsamen Verteilung
die Bestimmung der
einzelnen In- und Outdegree Verteilungen durch die Summationen
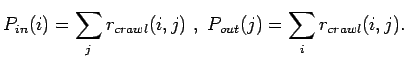 |
(4.1) |
Diese Summen stimmen
mit den zuvor in Abschnitt 3.4 bestimmten Verteilungen überein. In den folgenden
Abbildungen ist ein Ausschnitt von
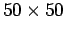 für die In- und
Outdegrees ausgehend vom Ursprung
gewählt, da dieser Bereich vollständig mit Daten belegt ist und
statistisch die größte Relevanz hat. Bedingt durch das Verfahren eines
Webcrawls (vgl. Abschnitt 3.2) werden nur Knoten mit
einem Indegree größer Null gefunden. Das später zu betrachtende Modell von
Krapivsky et al. macht keine Aussagen über Knoten mit einem Outdegree kleiner
Eins. Um in allen Darstellungen übereinzustimmen, wird jeweils ein
Urspung von (1,1) benutzt.
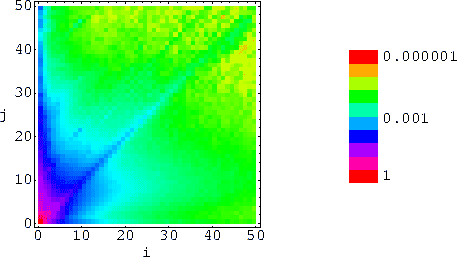
Die Abbildung 4.1 zeigt
die gemeinsame Verteilung der Knoten im Webcrawl mit dem Indegree an der
X-Achse, dem Outdegree an der Y-Achse, und dem Logarithmus der
Wahrscheinlichkeit solcher Knoten in der Färbung.
für die In- und
Outdegrees ausgehend vom Ursprung
gewählt, da dieser Bereich vollständig mit Daten belegt ist und
statistisch die größte Relevanz hat. Bedingt durch das Verfahren eines
Webcrawls (vgl. Abschnitt 3.2) werden nur Knoten mit
einem Indegree größer Null gefunden. Das später zu betrachtende Modell von
Krapivsky et al. macht keine Aussagen über Knoten mit einem Outdegree kleiner
Eins. Um in allen Darstellungen übereinzustimmen, wird jeweils ein
Urspung von (1,1) benutzt.
Die Abbildung 4.1 zeigt
die gemeinsame Verteilung der Knoten im Webcrawl mit dem Indegree an der
X-Achse, dem Outdegree an der Y-Achse, und dem Logarithmus der
Wahrscheinlichkeit solcher Knoten in der Färbung.
Nächste Seite: Die unkorrelierte Verteilung
Aufwärts: Gemeinsame In- und Outdegree
Vorherige Seite: Einleitung
Inhalt
Autor:Lutz-Ingo Mielsch