


Nächste Seite: Abbildungsverzeichnis
Aufwärts: Dokumentation
Vorherige Seite: Ein Webcrawl der Webseiten
Inhalt
Der WWW-Agent zur Vervollständigung der Outlinks jeder Seite
Zur Dokumentation und für eventuell folgende Untersuchungen von Webcrawls
der Suchmaschine ``Speedfind'' wird das Programm zur Vervollständigung der
Outlinks aller Seiten kurz kommentiert.
Das Programm ist in der Sprache PERL [40] (Practical Extraction and Report
Language) geschrieben. PERL ist speziell für den Umgang mit textbasierten
Daten konzipiert worden, wie es der HTML-Text (vgl. Tab. 3.4)
einer Webseite ist. Insbesondere sind die sogenannten ``Regular
Expressions'' ein mächtiges Werkzeug. Es soll hier jedoch nicht auf die
Sprache selbst eingegangen werden, sondern auf spezielle Probleme des
Konzeptes und der Anwendung.
Einleitend wird auf besondere Punkte bei der Anwendung des Programms eingegangen.
Bei dem Aufruf des Programms wird der Dateiname eines von ``Speedfind''
gelieferten Datensatzes übergeben (vgl. Tab. 3.3).
Dies würde genügen, wenn der Vorgang bei
 Seiten
schätzungsweise mehr als 6 Monate dauern dürfte. Diese langsame
Verarbeitung ist hauptsächlich auf diverse Webserver mit langen
Anwortzeiten zurückzuführen. Im Extremfall wartet das Programm bis zu 90
Sekunden auf eine Seite (vgl. Zeile 124 im Quelltext). Die Lösung des
Problems ist die Zerteilung der Daten in
Seiten
schätzungsweise mehr als 6 Monate dauern dürfte. Diese langsame
Verarbeitung ist hauptsächlich auf diverse Webserver mit langen
Anwortzeiten zurückzuführen. Im Extremfall wartet das Programm bis zu 90
Sekunden auf eine Seite (vgl. Zeile 124 im Quelltext). Die Lösung des
Problems ist die Zerteilung der Daten in 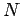 nicht allzugroße Dateien von
beispielweise jeweils 500000 Seiten-URLs. Dann kann dieses Programm, je nach
Leistungsfähigkeit des Computers, bis zu mal parallel gestartet
werden. Auf diese Art findet eine Lastverteilung auf verschiedene
Instanzen des Programms statt. Bei der Anwendung hat sich dieses Verfahren
als sehr effektiv bewiesen.
nicht allzugroße Dateien von
beispielweise jeweils 500000 Seiten-URLs. Dann kann dieses Programm, je nach
Leistungsfähigkeit des Computers, bis zu mal parallel gestartet
werden. Auf diese Art findet eine Lastverteilung auf verschiedene
Instanzen des Programms statt. Bei der Anwendung hat sich dieses Verfahren
als sehr effektiv bewiesen.
In den einzelnen Dateien mit Seiten-URLS sollten die Domains der Seiten
möglichst nicht sortiert, sondern stark gemischt enthalten sein. Die
Anwendung zeigte, daß sonst verschiedene Betreiber von Webservern durch
die zeitlich gebündelte, hohe Belastung ihres Servers gestört werden. Ebenso sollte das
Starten dieses Programms vorher beim zuständigen Rechenzentrum angekündigt
werden. Zum einen gibt es häufig Beschränkungen zum Datenaufkommen in
Netzwerken. In diesen Untersuchungen sind ingesamt mehr als 1.5TB Daten in
Form von Text aus dem Internet abgerufen worden. Zum anderen ist die
Belastung des des örtlichen DNS (Domain Name Service) extrem hoch und kann
zum Stillstand des lokalen Internet führen. Dies führte zu einigen
Problemen im Rechenzentrum der Universität.
Ein weiterer Faktor ist nicht zu unterschätzen. Das großräumige Abfragen
des WWW lenkt die Aufmerksamkeit vieler Betreiber von Webservern und
anderen Individuen auf den abfragenden Computer. Daher wird dieser
Computer überdurchschnittlich häufig Ziel von sogenannten Angriffen7.3 über
das Internet. Das Ziel socher Angriffe von sogenannten ``Hackern'' ist
Zugriff auf den Computer zu erlangen oder den Computer abstürzen zu
lassen. Daher sollte der Computer besonders geschützt7.4werden.
Aus den zuvor genannten Gründen und aufgrund der Möglichkeit allgemeiner
Computerausfälle ist das Programm so konzipiert, daß es weitestgehend in
der Lage ist nach einem
Abbruch fehlerfrei fortzufahren. Wird das Programm nach einem Abbruch neu
gestartet, erkennt es selbstständig den Abbruch und setzt die
Arbeit an der Unterbrechung fort. Sollte dies nicht mehr möglich sein,
endet das Programm mit einem Fehler und muß vom Anfang gestartet
werden.
Es sei hier noch erwähnt, daß sich das Programm nach jeweils
1000 untersuchten Webseiten neu startet, um den Speicherplatz (RAM, Cache,
etc.) zu initialsieren.
Die Vervollständigung des Webcrawls ist komplett, wenn alle
Instanzen des Programms fehlerfrei beendet sind.
Nächste Seite: Abbildungsverzeichnis
Aufwärts: Dokumentation
Vorherige Seite: Ein Webcrawl der Webseiten
Inhalt
Autor:Lutz-Ingo Mielsch

