


Nächste Seite: Zusammenfassung
Aufwärts: Schlußbetrachtung und Ausblick
Vorherige Seite: Grundlage erweiterter Modelle: Korrelationen
Inhalt
Das WWW konfrontiert Benutzer bereits heute mit einigen grundsätzlichen
Problemen. Die enorm dezentrale Form der Inhalte und deren ständiger
Wandel führen dazu, daß es derzeit unmöglich ist, eine detaillierte Karte
bzw. ein Inhaltsverzeichnis des WWW zu erstellen. Dieser Mangel macht das
Auffinden von Informationen besonders schwierig. Um diesem Problem zu
begegnen, sind Suchmaschinen ins Leben gerufen worden. Sie
starten typischerweise auf einer Seite des WWW, speichern die Inhalte in
einer Datenbank und folgen dann den Verweisen auf der Seite zu neuen
Seiten. Dort wiederholt sich dieser Vorgang, bis die Speicherkapzitäten
verbraucht sind oder der Vorgang zeitlich so weit fortgeschritten ist, daß
viele Seiten bereits eine starke inhaltliche Änderung erfahren
haben. Diesen Vorgang, bzw. dessen Ergebnis, nennt man ``Webcrawl''. Die
begrenzten Speicherkapazitäten stellen Suchmaschinen vor das Problem,
Seiten mit interessanten Informationen von solchen mit uninteressanten
Informationen zu unterscheiden. Darüber hinaus erfordert der Zeitdruck gute
Strategien um interessantere Seiten schneller zu finden.
Auch nachdem große Teile des WWW in Datenbanken gespeichert und für die
Suchanfragen von Benutzern zur Verfügung stehen, kehrt die Kernproblematik
zurück. Je nach Suchanfrage werden häufig einige hundert Webseiten in den
Datenbanken gefunden. Ein Benutzer möchte jedoch diese Seiten möglichst
nach Informationsgehalt sortiert angeboten bekommen, um möglichst schnell
genaue Antworten auf seine Anfrage zu finden. Daher bleibt trotz
Spezialisierung ein zentrales Problem von Suchmaschinen, wie wichtige
Seiten erkannt und möglichst schnell erreicht werden.
Motiviert durch den derzeit erfolgreichsten Algorithmus zur Bewertung der
Relevanz von Webseiten der Suchmaschine ``Google'' [22] wurden
Korrelationen zwischen den Indegrees benachbarter Knoten untersucht. Ein
wesentlicher Aspekt des Google-Algorithmus ist die Annahme, daß der Indegree
einer Seite in Verbindung zu deren Bedeutung steht. Daher können
Korrelationen zwischen den Indegrees benachbarter Knoten Aussagen
erlauben, welche Seiten eines Webcrawls potentiell auf interessante Seiten
verweisen und ob sich eine Vertiefung des Webcrawls an dieser Stelle lohnt. Solche
Aussagen könnten diesen Algorithmus und die Strategien von Suchmaschinen
zum Auffinden relevanter Seiten verbessern. In den ungerichteten
skalenfreien Netzwerken des Internet [38] und bei
Proteinnetzwerken [39] zeigte sich, daß Knoten mit niedrigem Degree
häufiger in der Nachbarschaft von Knoten mit hohem Degree existieren.
Besteht ein ähnlicher Zusammenhang zwischen dem Indegree eines Knotens des
WWW und dem mittleren Indegree der auf ihn verweisenden Knoten, dann würde
eine bevorzugte Auswertung von Seiten mit niedrigem Indegree des Webcrawls
häufiger zu relvanteren Seiten mit hohem Indegree führen.
In dieser Arbeit wurde für die Knoten des Webcrawls der
Zusammenhang zwischen dem Indegree eines Knotens und dem mittleren
Indegree seiner Nachbarn bestimmt. Dabei wurden nur die Nachbarn
betrachtet, die auf den Knoten verweisen
(Inlink-Nachbarschaft).
In einer weiteren Untersuchung wurden die Indegrees benachbarter Knoten
anhand der einzelnen Verbindungen zwischen den Knoten genauer betrachtet.
Dazu wurde die Häufigkeit von Verbindungen zwischen Knoten in Abhängigkeit
von dem Indegree des Zielknotens und dem Indegree des Quellknotens
bestimmt. In einem ersten Schritt wurde diese Verteilung mit der Näherung
der Linkverteilung ohne Korrelationen zwischen den Indegrees benachbarter
Knoten und ohne Korrelationen zwischen dem In- und Outdegree eines Knotens verglichen.
In einem weiteren Schritt wurden die Korrelationen zwischen dem In- und
Outdegree eines Knotens in die Näherung mit einbezogen.
Die erste Untersuchung der Inlink-Nachbarschaft ergab, daß der Indegree eines
Knotens und der mittlere Indegree seiner Nachbarschaft nicht korreliert
sind. Bei den genaueren, ungemittelten Betrachtungen der Linkstatistik wurden Korrelationen zwischen
den Indegrees verbundener Knoten gefunden. Jedoch zeigte sich in der
zweiten Näherung, daß diese im wesentlichen aus den Korrelationen
zwischen dem In- und Outdegree der Knoten stammen. Die verbleibenden
schwachen Korrelationen entsprechen dem gesuchten Zusammenhang zwischen
den Indegrees benachbarter Knoten. Es konnte eine leichte Neigung
beobachtet werden, daß Seiten mit beliebigen Indegree eher zu Seiten mit höherem
Indegree verweisen. Ein stärkerer Unterschied zeigte sich bei Seiten mit
einem Indegree größer als 40. Diese Seiten sind allgemein seltener Ursprung von
Verweisen. Dieser Unterschied konnte als Hinweis auf eine professionellere
Gestaltung dieser Seiten interpretiert werden, da Lehrbücher zum Webdesign
[37] die Verwendung von wenigen Outlinks pro Seite empfehlen.
Unter dieser Annahme
können Verbesserungen für die Crawl-Strategien von Suchmaschinen abgeleitet
werden.
Die Inhalte professionell gestalteter Seiten werden vermutlich gezielter gewählt oder sogar
redaktionell bearbeitet. Daher kann davon ausgegangen werden, daß diese
Seiten relevantere Verweise enthalten. Bei der Erstellung eines Webcrawls
könnten daher Verweise von Seiten mit einem Indegree größer 40 bevorzugt verfolgt
und auf diese Weise interessantere Seiten schneller gefunden
werden.
Das Fehlen von Korrelationen zwischen dem Indegree einer Seite und dem
mittleren Indegree der Inlink-Nachbarn stellt einen Unterschied zu den ungerichteten
skalenfreien Netzwerken des Internet [38] und der
Proteinnetzwerke [39] dar. Dort wurde für den Zusammenhang
zwischen dem Degree 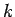 eines Knoten und dem mittleren Degree
eines Knoten und dem mittleren Degree 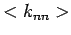 jeweils ein Potenzgesetz
jeweils ein Potenzgesetz
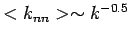 gefunden. Obwohl ein
Vergleich mit dem gerichteten Netzwerk des WWW nur bedingt möglich ist,
geben diese unterschiedlichen Korrelationen einen Hinweis darauf, daß sich
diese Netze in ihrer Topologie vom WWW unterscheiden.
gefunden. Obwohl ein
Vergleich mit dem gerichteten Netzwerk des WWW nur bedingt möglich ist,
geben diese unterschiedlichen Korrelationen einen Hinweis darauf, daß sich
diese Netze in ihrer Topologie vom WWW unterscheiden.
Desweiteren kann die erstellte Stichprobe des WWW Grundlage für weitere
Untersuchungen des WWW sein.
Nächste Seite: Zusammenfassung
Aufwärts: Schlußbetrachtung und Ausblick
Vorherige Seite: Grundlage erweiterter Modelle: Korrelationen
Inhalt
Autor:Lutz-Ingo Mielsch