


Nächste Seite: Schlußbetrachtung und Ausblick
Aufwärts: Die Korrelationen im Webcrawl
Vorherige Seite: Die unkorrelierte Verteilung
Inhalt
Eine mögliche Ursache für die Abweichungen von der Näherung
(5.2) könnten die Korrelationen
zwischen In- und Outdegree eines Knotens sein, wie sie im vorhergehenden Kapitel
beobachtet wurden. Dort zeigte sich beim Vergleich zwischen dem Webcrawl
und einem Netzwerk ohne Korrelationen zwischen den Degrees eines Knotens eine
deutlich höhere Präsenz von Knoten mit hohem In- und Outdegree. Wenn
jedoch Knoten mit hohem Indegree stärker dazu tendieren, auch einen hohen Outdegree
zu haben, dann erscheinen diese Knoten auch häufiger als Ursprung von
Links.
Daher wird in einer weiteren Näherung diese Korrelationen zwischen
Outdegree 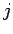 und Indegree
und Indegree  eines Knotens mit einbezogen. Dazu wird
die Anzahl der Outlinks eines Knotens unter der Bedingung, daß dessen
Indegree gleich ist, betrachtet, d.h.
eines Knotens mit einbezogen. Dazu wird
die Anzahl der Outlinks eines Knotens unter der Bedingung, daß dessen
Indegree gleich ist, betrachtet, d.h.
 . Mit der Anzahl
. Mit der Anzahl
 von Knoten mit Indegree , ist die
Wahrscheinlichkeit, daß ein Link seinen Ursprung bei einem Knoten mit
Indegree hat, gleich
von Knoten mit Indegree , ist die
Wahrscheinlichkeit, daß ein Link seinen Ursprung bei einem Knoten mit
Indegree hat, gleich
 |
(5.3) |
Für die bedingte Wahrscheinlichkeit gilt
 . Die
Wahrscheinlichkeit, daß ein Link bei einem Knoten mit Indegree
. Die
Wahrscheinlichkeit, daß ein Link bei einem Knoten mit Indegree  endet,
bleibt wie zuvor
endet,
bleibt wie zuvor
 . Damit ist die
Wahrscheinlichkeit, einen Link von einem Knoten mit Indegree zu einem
Knoten mit Indegree zu finden,
. Damit ist die
Wahrscheinlichkeit, einen Link von einem Knoten mit Indegree zu einem
Knoten mit Indegree zu finden,
 |
(5.4) |
Die Verteilungen 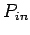 des ersten
Faktors der rechten Seite heben sich auf. Mit der mittleren
Konnektivität
des ersten
Faktors der rechten Seite heben sich auf. Mit der mittleren
Konnektivität  erhält die Näherung der Verteilung
erhält die Näherung der Verteilung
 unter
Berücksichtigung der Korrelationen zwischen dem In- und Outdegree eines
Knotens die Form
unter
Berücksichtigung der Korrelationen zwischen dem In- und Outdegree eines
Knotens die Form
 |
(5.5) |
Wiederum ist diese Verteilung als Norm für die gemessenen Werte angewendet
worden und in Abbildung 5.5 dargestellt.
Abbildung:
Verteilung der Links
 in Abhänigikeit vom Indegree des Quellknotens
und vom Indegree des Zielknotens , normiert mit der
Näherung
in Abhänigikeit vom Indegree des Quellknotens
und vom Indegree des Zielknotens , normiert mit der
Näherung  (5.5) für Netzwerke mit Korrelationen
zwischen dem In-/Outdegree eines Knotens und ohne Korrelationen zwischen den Indegrees benachbarter Knoten.
(5.5) für Netzwerke mit Korrelationen
zwischen dem In-/Outdegree eines Knotens und ohne Korrelationen zwischen den Indegrees benachbarter Knoten.
 |
Man erkennt
bereits, daß die Verteilung des Webcrawls deutlich besser wiedergegeben wird als zuvor.
Die Korrelationen aus Abb. 5.4 stammen demnach
zu einem großen Teil aus den Korrelationen zwischen In- und Outdegree der einzelnen
Knoten, wie sie bereits im vorhergehenden Kapitel
untersucht wurden. Hier sind jedoch weitergehende Korrelationen gesucht.
Wie bei der gemeinsamen Verteilung 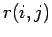 von Knoten mit Indegree
von Knoten mit Indegree 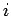 und Outdegree fällt auch hier in der Diagonalen eine deutliche
Überrepräsentation auf. Demnach gibt es auch eine überdurchschnittlich
hohe Anzahl
an Links zwischen Knoten mit identischem Indegree. Das Unterstützt die
bereits zuvor gemachte Annahme (vgl. Abschnitt 4.5), daß
die Ursache Websites mit Navigationsleisten sind. Dadurch das
und Outdegree fällt auch hier in der Diagonalen eine deutliche
Überrepräsentation auf. Demnach gibt es auch eine überdurchschnittlich
hohe Anzahl
an Links zwischen Knoten mit identischem Indegree. Das Unterstützt die
bereits zuvor gemachte Annahme (vgl. Abschnitt 4.5), daß
die Ursache Websites mit Navigationsleisten sind. Dadurch das
 Seiten eine solche Liste von Links auf alle anderen
Seiten eine solche Liste von Links auf alle anderen  Seiten einer
Website haben, erzeugt jeder derartige Cluster in dieser Linkstatistik
entsprechend
Seiten einer
Website haben, erzeugt jeder derartige Cluster in dieser Linkstatistik
entsprechend  Links zwischen Knoten mit identischem Indegree .
Links zwischen Knoten mit identischem Indegree .
Außerhalb des Einflusses der Diagonalen erscheinen große, ebene Bereiche
mit Werten um
 . Die Bereiche von
. Die Bereiche von
 werden nicht in
die folgenden Betrachtungen einbezogen, da diese durch Randeffekte
verändert sein können (vgl. Abschnitt 4.5).
werden nicht in
die folgenden Betrachtungen einbezogen, da diese durch Randeffekte
verändert sein können (vgl. Abschnitt 4.5).
Insgesamt ist eine leichte Tendenz erkennbar, daß Seiten mit einem Indgree
zu Seiten mit einem höheren Indegree  verweisen. Eine
mögliche Erklärung soll folgendes Beispiel veranschaulichen: Die Webseiten
einzelner Personen (Homepages) sind im allgemeinen relativ unbekannt. Auf
diesen Homepages sind sogenannte Linksammlungen beliebt. Das sind
typischerweise eine Reihe von Verweisen auf Webseiten von persönlichem
Interesse des Besitzers. Bei einem Fußballfan wird diese Linksammlung
vermutlich einen Verweis auf die Webseite seines Lieblingsvereins
enthalten, sowie Verweise auf andere Seiten, die für Fußballfans
interessant sind. Auf diese Seiten werden jedoch viele Fußballfans
verweisen. Hingegen werden diese allgemeinen Fußballseiten nicht,
oder zumindest seltener, auf einzelne Fans verweisen.
verweisen. Eine
mögliche Erklärung soll folgendes Beispiel veranschaulichen: Die Webseiten
einzelner Personen (Homepages) sind im allgemeinen relativ unbekannt. Auf
diesen Homepages sind sogenannte Linksammlungen beliebt. Das sind
typischerweise eine Reihe von Verweisen auf Webseiten von persönlichem
Interesse des Besitzers. Bei einem Fußballfan wird diese Linksammlung
vermutlich einen Verweis auf die Webseite seines Lieblingsvereins
enthalten, sowie Verweise auf andere Seiten, die für Fußballfans
interessant sind. Auf diese Seiten werden jedoch viele Fußballfans
verweisen. Hingegen werden diese allgemeinen Fußballseiten nicht,
oder zumindest seltener, auf einzelne Fans verweisen.
Ein weiterer Unterschied zeigt sich bei  . Seiten mit einem
Indegree jenseits von 40 scheinen allgemein seltener auf andere Seiten zu verweisen. Eine
denkbare Ursache ist, daß Webseiten ab einem bestimmten
Bekanntheitsgrad besser organisiert werden. Wie
bereits in Abschnitt 4.5 erwähnt, empfehlen professionelle
Lehrbücher zum Webdesign [37], nur 8 bis 10 Outlinks pro
Seite zu verwenden.
. Seiten mit einem
Indegree jenseits von 40 scheinen allgemein seltener auf andere Seiten zu verweisen. Eine
denkbare Ursache ist, daß Webseiten ab einem bestimmten
Bekanntheitsgrad besser organisiert werden. Wie
bereits in Abschnitt 4.5 erwähnt, empfehlen professionelle
Lehrbücher zum Webdesign [37], nur 8 bis 10 Outlinks pro
Seite zu verwenden.
Anders als bei der Betrachtung in Abschnitt 5.2 lassen sich also
bei differenzierterer Analyse leichte Korrelationen zwischen den Indegrees
benachbarter Knoten finden.
Unter der Annahme, daß die hier beobachteten Korrelationen und deren
Ursachen hinreichend bedeutend sind, wären Verbesserungen für die
Verfahren zur Bewertung und Suche von Webseiten denkbar. Es erscheint
naheliegend, daß eine professioneller betreute Seite überdurchschnittlich
differenzierte und aktuelle Informationen bietet. Bei der Bewertung der
Relevanz von Seiten könnten daher Seiten ab 40 Inlinks stärker gewichtet werden.
Ebenso könnten bei der Erstellung
eines Webcrawls die Outlinks von Seiten ab 40 Inlinks bevorzugt
untersucht werden, da diese Seiten wahrscheinlich auch eine wertvollere Auswahl von Verweisen auf
Inhalte bieten.
Nächste Seite: Schlußbetrachtung und Ausblick
Aufwärts: Die Korrelationen im Webcrawl
Vorherige Seite: Die unkorrelierte Verteilung
Inhalt
Autor:Lutz-Ingo Mielsch