


Nächste Seite: Modelle
Aufwärts: diplom
Vorherige Seite: Inhalt
Inhalt
Ein weites Spektrum von physikalischen Systemen läßt sich durch komplexe,
netzartige Strukturen beschreiben. Bespielsweise lassen sich die Vorgänge
in lebenden Zellen gut durch ein Netz aus Proteinen und deren
Wechselwirkungen beschreiben [1], ebenso ist das Internet
ein komplexes Netzwerk aus Routern und Computern mit physischen
Kommunikationswegen [2,3] zwischen ihnen. Das
World-Wide-Web (WWW) bildet mit seinen Webseiten als Knoten und den
Hyperlinks zwischen diesen Seiten ebenfalls ein riesiges Netzwerk
[4]. Die unerwarteten
Ergebnisse von Untersuchungen an diesen und vielen weiteren Systemen
veranlaßten Wissenschaftler, sich auf die Suche nach den Mechanismen
hinter dem Aufbau dieser komplexen Systeme zu machen.
Die Physik hat eine Vielzahl von Verfahren hervorgebracht, die das
Verhalten eines Systems als Ganzes aus den lokalen Eigenschaften der
einzelnen Bestandteile herleiten.
Der Erfolg
dieser Modelle basiert auf den einfachen Wechselwirkungen zwischen den
Bestandteilen: es ist jeweils klar, welche Teile miteinander wechselwirken
und wie stark diese Wechselwirkungen sind. Im Gegensatz dazu fehlen die
Mittel, um Systeme zu beschreiben, deren Wechselwirkungen unklarer sind. Das
sind zum Beispiel Systeme, in denen offen bleibt, ob zwei bestimmte
Komponenten miteinander wechselwirken.
Obwohl in vielen realen komplexen Systemen solche Unklarheit existiert,
zeigte sich in den vergangenen Jahren zunehmend, daß die Statistische
Physik auch für diese Systeme den idealen Rahmen zu deren
Beschreibung darstellt. So wurden einige mikroskopische Mechanismen
[5,6,7,8] vorgestellt, die das
makroskopische Verhalten des Systems wiedergeben.
Seit etwa 1950 bezeichnet man große Netzwerke ohne Regelmäßigkeiten in
deren Aufbau als ``Zufallsgraphen'' (Random Graphs). Diese Zufallsgraphen
stellen die einfachste Form eines komplexen Netzwerks dar und wurden
zuerst von den Mathematikern P. Erdös und A. Rényi [9]
studiert. In dem Modell von Erdös und Rényi (ER Modell) wird mit
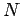 Knoten begonnen und dann jedes Paar Knoten mit der Wahrscheinlichkeit
Knoten begonnen und dann jedes Paar Knoten mit der Wahrscheinlichkeit
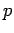 verbunden, so daß der entstehende Graph etwa
verbunden, so daß der entstehende Graph etwa  zufällig verteilte
Verbindungen (Links) enthält. Dieses Modell bestimmte Jahrzehnte das
Denken über Netzwerke und wurde erst durch das neue, zunehmende Interesse
an diesen Systemen neu überdacht. Es stellte sich die Frage, ob die
komplexen Wechselwirkungs-Netzwerke einer Zelle, des Internet oder des WWW
wirklich zufällig aufgebaut sind. Die Intuition erwartet, daß besondere
Prinzipien bei deren Aufbau am Werke sein müssen und daß sich diese
besondere Organisation in den topologischen Eigenschaften des Netzwerks
widerspiegeln müßte. Wenn die Topologie dieser Netzwerke tatsächlich von
denen der Zufallsgraphen abweicht, dann werden jedoch neue
Begrifflichkeiten und Definitionen nötig, um die Abweichungen quantitativ
erfassen zu können.
zufällig verteilte
Verbindungen (Links) enthält. Dieses Modell bestimmte Jahrzehnte das
Denken über Netzwerke und wurde erst durch das neue, zunehmende Interesse
an diesen Systemen neu überdacht. Es stellte sich die Frage, ob die
komplexen Wechselwirkungs-Netzwerke einer Zelle, des Internet oder des WWW
wirklich zufällig aufgebaut sind. Die Intuition erwartet, daß besondere
Prinzipien bei deren Aufbau am Werke sein müssen und daß sich diese
besondere Organisation in den topologischen Eigenschaften des Netzwerks
widerspiegeln müßte. Wenn die Topologie dieser Netzwerke tatsächlich von
denen der Zufallsgraphen abweicht, dann werden jedoch neue
Begrifflichkeiten und Definitionen nötig, um die Abweichungen quantitativ
erfassen zu können.
Die Fortschritte der letzten Jahre in diesem Bereich wurden wesentlich
unterstützt von der zunehmenden Verbreitung der Computer in großen
Gebieten des alltäglichen Lebens und den damit entstandenen riesigen
Datenbanken zur Beschreibung komplexer Systeme. Ebenso wurden die Untersuchungen an
großen Netzwerken erst mit
den deutlich gestiegenen Rechnerkapazitäten möglich.
Unterstützt von diesen Entwicklungen sind bereits viele Eigenschaften
definiert und gemessen worden. Gegenwärtig sind bei der Betrachtung
komplexer Netzwerke drei konzeptionelle Eigenschaften von besonderer
Bedeutung. Diese Begriffe werden im Abschnitt 2.1
noch ausführlich behandelt, hier aber kurz erläutert.
Clustering: Eine bekannte Eigenschaft von sozialen Netzwerken ist die
Cliquenbildung. In einer Clique aus Freunden oder Bekannten kennt jeder
Einzelne alle Anderen. Diese Neigung, Gruppen (Cluster) zu bilden wird
durch den Clustering-Koeffizient [10] ausgedrückt.
Der Koeffizient drückt das Verhältnis zwischen den vorhandenen
Verbindungen eines Knoten zu seinen Nachbarn und der Anzahl möglicher
Verbindungen zwischen diesen Knoten aus.
In Zufallsgraphen entspricht der Clustering-Koeffizient  , da jede einzelne
der möglichen Verbindungen mit der Wahrscheinlichkeit existiert. In
den meisten realen Netzwerken ist der Clustering-Koeffizient deutlich größer
als bei Zufallsgraphen mit der gleichen Anzahl Knoten und
Verbindungen.
, da jede einzelne
der möglichen Verbindungen mit der Wahrscheinlichkeit existiert. In
den meisten realen Netzwerken ist der Clustering-Koeffizient deutlich größer
als bei Zufallsgraphen mit der gleichen Anzahl Knoten und
Verbindungen.
Small-World: Die Small-World-Eigenschaft [11] bezeichnet den Effekt, daß
auch in großen Netzwerken zwischen zwei beliebigen Knoten
ein relativ kurzer Pfad existieren kann. Der Abstand zweier Knoten ist
als die Anzahl der einzelnen Verbindungen auf dem kürzesten Weg zwischen diesen Knoten
definiert. Diese Eigenschaft wird in den meisten komplexen Systemen,
einschließlich Zufallsgraphen, gefunden und ist daher kein Indikator für
besondere Mechanismen bei der Organisation des Netzwerks. Dennoch ist
dieser Begriff für die spätere Definition der Small-World-Netzwerke nützlich.
Small-World-Netzwerke zeichnen sich zusätzlich durch einen
hohen Clustering-Koeffizienten aus.
Degree-Verteilung: Die Anzahl an Verbindungen, die ein bestimmter
Knoten mit anderen Knoten in einem Netzwerk hat, bezeichnet man als
Degree des Knotens. Die Wahrscheinlichkeit, daß ein
zufällig ausgewählter Knoten gerade einen Degree von 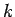 hat, wird durch die
Verteilung
hat, wird durch die
Verteilung  bestimmt. Bei Zufallsgraphen werden alle
Verbindungen zufällig geknüpft und daher besitzt der größte Teil aller
Knoten einen Degree nahe dem mittleren Degree
bestimmt. Bei Zufallsgraphen werden alle
Verbindungen zufällig geknüpft und daher besitzt der größte Teil aller
Knoten einen Degree nahe dem mittleren Degree  des Netzwerks. Die
Degree-Verteilung von Zufallsgraphen entspricht einer Poisson-Verteilung
mit dem Maximum bei . Im Gegensatz dazu zeigen sich in den meisten
realen Netzwerken deutliche Abweichungen von dieser Verteilungsform. In
vielen Netzwerken findet man eine Verteilung nach einem Potenz-Gesetz
des Netzwerks. Die
Degree-Verteilung von Zufallsgraphen entspricht einer Poisson-Verteilung
mit dem Maximum bei . Im Gegensatz dazu zeigen sich in den meisten
realen Netzwerken deutliche Abweichungen von dieser Verteilungsform. In
vielen Netzwerken findet man eine Verteilung nach einem Potenz-Gesetz
 |
(1.1) |
Diese Netzwerke werden skalenfreie Netzwerke genannt
[5]. Einge der bekanntesten Beispiele sind in Tabelle
1.1 aufgeführt.
Tabelle 1.1:
Die charakteristischen Exponenten einiger Degree-Verteilungen
von skalenfreien Netzwerken, deren Verteilungen der Form
(1.1) entsprechen. Es sind die Größe des Netzwerks, der
mittlere Degree , der Exponent der Indegree-Verteilung 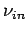 ,
der Exponent der Outdegree-Verteilung
,
der Exponent der Outdegree-Verteilung
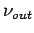 und die mittlere kürzeste Weglänge
und die mittlere kürzeste Weglänge  angegeben. Die
gerichteten Netzwerke sind mit
angegeben. Die
gerichteten Netzwerke sind mit
 gekennzeichnet. Für
ungerichtete Netzwerke sind die Exponenten der Indegree- und Outdegree-Verteilung als identisch angegeben.
gekennzeichnet. Für
ungerichtete Netzwerke sind die Exponenten der Indegree- und Outdegree-Verteilung als identisch angegeben.
|
|
Diese drei Eigenschaften Small-World-Eigenschaft , Clustering und
Degree-Verteilung haben
in den letzten Jahren zu einer Neuauflage der Netzwerkmodellierung
geführt. Heute werden drei Hauptklassen von Netzwerken und deren Modelle unterschieden
- Zufallsgraphen werden immer noch häufig angewendet und dienen
bei empirischen Untersuchungen und Modellstudien als
Vergleichsnetzwerke.
- Small-World Netzwerke zeigen den Small-World-Effekt und einen
deutlich größeren Clustering-Koeffizienten als Zufallsgraphen. Diese Netzwerke
sind zwischen regulären Gittern und Zufallsgraphen angesiedelt.
- Netzwerke mit Degree Verteilungen die deutlich von der
Poissonverteilung abweichen. Insbesondere skalenfreie Netzwerke
bilden eine große Klasse dieser Netzwerke.
Innerhalb dieser Klassen werden die Netzwerke nach einem weiteren
wichtigen Merkmal unterschieden. Je nach Natur eines Netzwerks sind die
Verbindungen zwischen Knoten gerichtet (unidirektional) oder ungerichtet
(bidirektional). Ein Bekanntschaftsnetzwerk wird üblicherweise als
ungerichtet betrachtet. Dort stellt ein Knoten jeweils eine Person dar und
es existiert eine Verbindung zwischen zwei Knoten, wenn sich beide kennen.
Im Gegensatz dazu sind Zitat-Netzwerke gerichtet. Bei wissenschaftlichen
Veröffentlichungen repräsentieren die Artikel einzelne Knoten und die
Verbindungen werden vom zitierenden Artikel zum zitierten Artikel geknüpft,
jedoch nicht umgekehrt.
Das Ziel dieser Diplomarbeit ist es, Korrelationseigenschaften des größten
allgemein zugänglichen skalenfreien Netzwerks zu
untersuchen, des World-Wide-Web. Darin bilden die Webseiten (HTML Seiten) die Menge der Knoten
und die Hyperlinks zwischen Webseiten stellen die gerichteten Verbindungen dar. Ein
vollständiges Abbild des WWW mit einer Größe von schätzungsweise  Webseiten kann nicht erstellt werden [4]. Daher wird als
Grundlage der Untersuchungen in Kapitel 3 eine
repräsentative Stichprobe des WWW erstellt.
Webseiten kann nicht erstellt werden [4]. Daher wird als
Grundlage der Untersuchungen in Kapitel 3 eine
repräsentative Stichprobe des WWW erstellt.
Ein Hyperlink ist nur auf der Webseite, von welcher er ausgeht, verankert
und zeigt auf eine andere Seite. Das WWW ist daher ein gerichtetes
Netzwerk. Im Gegensatz zu einem ungerichteten Netzwerk können Knoten in
einem gerichteten Graphen nicht nur durch einen einzigen Degree
beschrieben werden, sondern auch durch den jeweiligen Anteil von
ankommenden (Indegree) und abgehenden (Outdegree) Verbindungen. Die
Verteilungen der einzelnen Anteile sind bereits gut untersucht und zeigen
beide ein Potenzgesetz (Tab. 1.1, Abschnitt 3.4). Darüber
hinaus wird in Kapitel 2 anhand einer Reihe von Modellen
vorgestellt, welche generische Mechanismen übereinstimmende Verteilungen
erzeugen.
Für die Bildung neuer oder die Untermauerung von bestehenden Modellen zur
Beschreibung der Topologie des WWW ist es nun notwendig geworden, detailliertere
Informationen aus realen Netzen zu bestimmen. Eine wesentliche ungeklärte
Frage ist, ob die Verteilungen der Indegrees und der Outdegrees korreliert
sind. In diesem Zusammenhang wurde bereits häufig beklagt
[21,6,8], daß keinerlei empirische Erkenntnisse
bezüglich der Verteilung von Knoten in Abhängigkeit von deren Indegree
und deren Outdegree existieren. Das Fehlen empirischer
Untersuchungen führte dazu,
daß diese Verteilung bisher nur unter theoretischen Annahmen beleuchtet
[6,8] werden konnte und entbehrt daher empirischen
Fundamenten. Diesem Problem ist das 4. Kapitel dieser
Arbeit zugeordnet.
Das WWW ist zunehmend eines der wichtigsten Kommunikationsmedien der
Welt. Mit eben dieser Entwicklung ensteht jedoch ein wachsendes Problem:
Die Auffindbarkeit von Informationen. Jede Suchmaschine
überblickt heute kaum mehr als einen Bruchteil des WWW. Alle Suchmaschinen
zusammengenommen decken schätzungsweise kaum mehr als die Hälfte des
allgemein verfügbaren WWW ab [4]. Eines der Hauptprobleme der
Suchmaschinen ist neben dem Umgang mit enormen Datenmengen, die
Aktualität der Daten. Der ständige Wandel des WWW zwingt Suchmaschinen
dazu, alle gesammelten Daten in bestimmten Zeitintervallen neu abzurufen.
Dies führt dazu, daß selbst die größten derzeitigen Suchmaschinen
hauptsächlich mit der Aktualisierung ihres Datenbestandes beschäftigt
sind. Um dennoch möglichst vielen Benutzern die gesuchten Informationen
bieten zu können, wird versucht die Datenmenge nach Relevanz zu
klassifizieren und zu sortieren. Ein erfolgreicher Ansatz wurde von
S. Brin und L. Page [22] bei der Entwicklung der Suchmaschine ``Google''
verwendet. Dort wird die Verbindungsstruktur des WWW benutzt, um Aussagen
über die Relevanz einer Seite zu machen. Insbesondere spielt die Anzahl
von Verbindungen zu einer Seite eine wesentliche Rolle in deren
Bewertung. In diesem Zusammenhang ist ein interessanter Aspekt der
Topologie des WWW die Organisation der Seiten nach deren Indegree, um
die Entwicklung von Verfahren zur effektiveren Suche und Bewertung von Informationen
zu ermöglichen. Zu diesem Zweck werden in Kapitel 5
Korrelationen zwischen den Indegrees benachbarter Seiten untersucht.
In dem
abschließenden 6. Kapitel werden die Ziele und Ergebnisse zusammengefaßt
und deren Bedeutung erläutert.
Nächste Seite: Modelle
Aufwärts: diplom
Vorherige Seite: Inhalt
Inhalt
Autor:Lutz-Ingo Mielsch